I have been on the UI Infrastructure team at DigitalOcean since November 2021. One of my main responsibilities is acting as the primary maintainer of our internal React component library, Walrus. This library predates my involvement by several years, and it has been interesting getting to see how previous design choices have played out.
This document is a collection of my thoughts on maintaining a component library as part of an existing design system used by a large number of frontend applications. I don’t particularly care much for visual design—though I seem effective at implementing it—and am more interested in the software engineering and social challenges of building a large-scale component library.
I’ll probably update this page as I have further insight.
Philosophy
When maintaining a library like this, I’m trying to understand the subtle incentives offered through the interface. If a developer can pull a lever, it will eventually get pulled. Sometimes that developer is the most senior person on the team. Sometimes it’s the one fresh out of a boot camp. There are hundreds of thousands of lines of code, a task to be completed, and too much context required to know The Right Thing. This problem spawns out of large team dynamics, and it is present in every organization. If the lever exists, it gets pulled.
But the responsibility doesn’t entirely fall on the developer who saw the lever. The burden must also fall on the developer who offered it. Good design results in library consumers falling into the pit of success. Planning for this outcome requires patient consideration, which I do not rush. Generally speaking, everything in this document boils down to me maximizing the following:
- It should be easy to take a design and translate it into UI code. Props should map intuitively to design system documentation in Figma or otherwise. Components should look correct without applying overrides.
- A component should, for the most part, act as an opaque box to a parent consuming it. It should not leak details about its internals or allow injecting arbitrary code/styles. Data goes in; markup comes out.
- The Obvious Thing, The Easy Thing, and The Right Thing should overlap most of the time. A developer under time pressure is usually going to reach for the easiest solution. Ideally, the easiest solution is the obvious one. And the obvious should be what I wanted the developer to do in the first place.
- Doing The Wrong Thing should be at least uncomfortable, at worst impossible. Allow for escape hatches when necessary, but make them feel bad. The developer should think, “I should open an issue so that I don’t have to do this again.”
That said, none of the rules in this document are hard and fast. They have their tradeoffs which usually boil down to me favoring design system consistency over stylistic flexibility. Keep that in mind as you read on.
Finally, I don’t think the tradeoffs taken here should necessarily apply (but maybe they do?) to a general-purpose, open-source component library because the motivations are different. Those libraries should be flexible enough that company A can use them and not look like company B. In my case, Walrus just needs to look like my company, and I don’t want the component library to be able to escape looking like my company.
When everyone owns it, nobody owns it.
In my exceptionally strong opinion, someone has to own the component library. Without an owner, the component library will accumulate one-off “I just need this one thing” type changes that, when grouped, do not mirror a holistic view of the design system. At least one developer’s job description must be the maintenance of the component library.
For example, let’s say that a product engineer receives some new design they must implement. It might contain a variant of a component that is maybe in the design system but not yet implemented in the component library. This incompleteness is a big problem because the product engineer must do something about the component library they aren’t responsible for maintaining. Without a dedicated owner, the implemented solution is usually The Easy Thing (which is generally The Wrong Thing):
- Update the component just enough to get the desired result and nothing more. Slows down developers in the future because they must often inspect the component internals to understand the various one-off props present in the interface.
- Don’t update the component and wrap it with
styled-componentsor otherwise. Creates fragmentation because these changes rarely make it back into the component library. - Go rogue and implement something else from scratch. Often doesn’t consider solved edge-cases that might already exist in the library.
These kinds of solutions tend to compound. Changes to the component now require extra diligence because existing overrides may become the location of breaking visual changes, so it’s easier not to touch it. And it keeps going like this. As more overrides are applied, stylistic changes become riskier and riskier to apply safely ⚰️. If you currently work at a company with a component library owned by nobody, I am confident you feel this pain.
TL;DR someone needs to lose their job if the component library sucks; otherwise, it will probably suck.
A component interface concisely representing the variants of the design system is easier to use.
While scanning through a design document, I try to see if I can “visualize” all variations as if they were axes in an N-dimensional space where each dimension correlates to a single property.
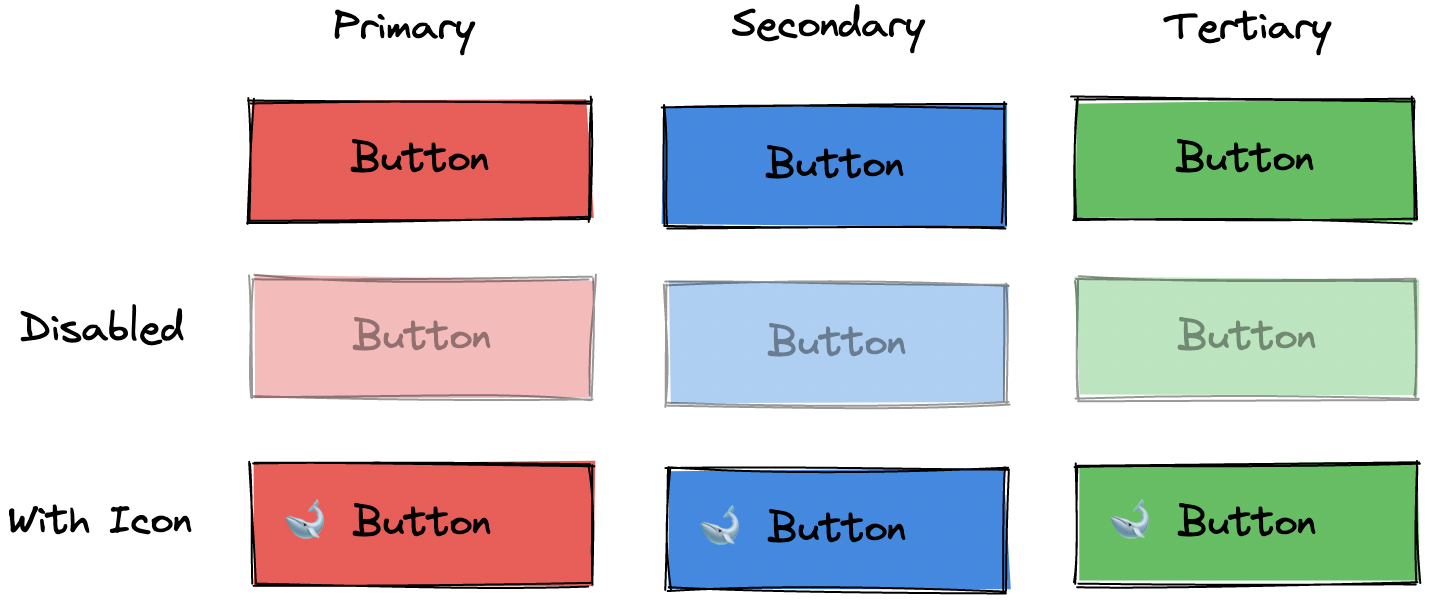
It’s essential to understand which visual differences operate independently and which do not. For example, the type and disabled props of a Button are independent (orthogonal?) of each other. A designer would (hopefully) never suggest that “a secondary Button can’t be disabled.”
type Props = {
type?: 'primary' | 'secondary' | 'tertiary';
disabled?: boolean;
icon?: Icon;
/* ... */
}
export Button: React.FC<Props> = (props) => {
/* ... */
};
Contrastingly, differences that depend on each other should merge into a single prop—and that single prop should operate as its own dimension. For example, a TextInput that optionally has a label where the label can also optionally have a tooltip.
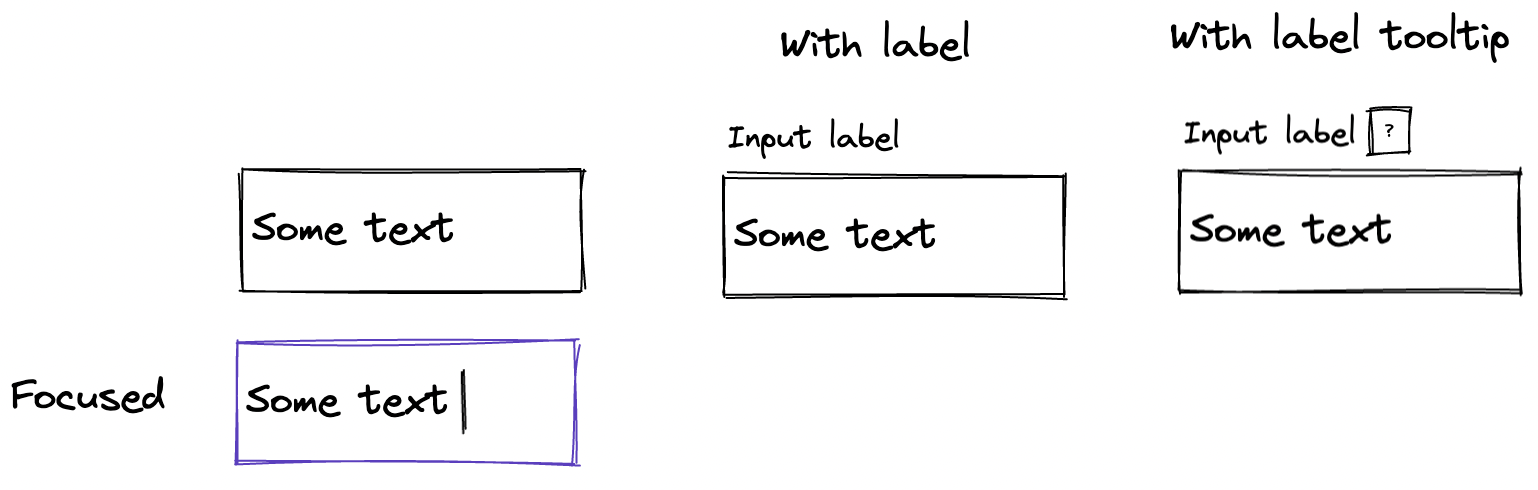
It does not make sense for the interface to have two props, label and labelTooltip, because the tooltip won’t show without the label. They should be merged into a single prop to capture this requirement:
// ❌ Does not indicate that `labelTooltip` depends on `label`!
type Props = {
label?: string;
labelTooltip?: string;
/* ... */
}
// ✅ `tooltip` cannot exist without `text`!
type Props = {
label?: string | { text: string; tooltip?: string };
}
export TextInput: React.FC<Props> = (props) => {
const label = props.label ? normalizeLabel(props.label) : null;
/* ... */
};
This typing is reminiscent of one of my all-time favorite programming isms: “make illegal states unrepresentable”. If we assume that the design system represents all possible “legal visual states”, then the props should not allow for illegal visual states.
Someone could argue, “well, if the label isn’t present, then the component won’t show the tooltip, and the presentation remains valid.” Furthermore, someone could also add a runtime check which would enforce the invariant.
But why wait until runtime? Why wait for another developer to become confused? This laziness pushes the responsibility of correctness onto the developer (and every developer after). According to the type checker, <TextInput labelTooltip="!"/> is entirely valid. There is an implied rule in this code where the tooltip cannot exist without the label, clearly stated by the type { text: string; tooltip?: string }.
In the most extreme case, a component might require a prop interface that switches on a single key, not unlike a Redux reducer switching on action.type. In such a scenario, it would make more sense to create several different components instead (possibly with a common, internal base component).
Components should probably not position themselves.
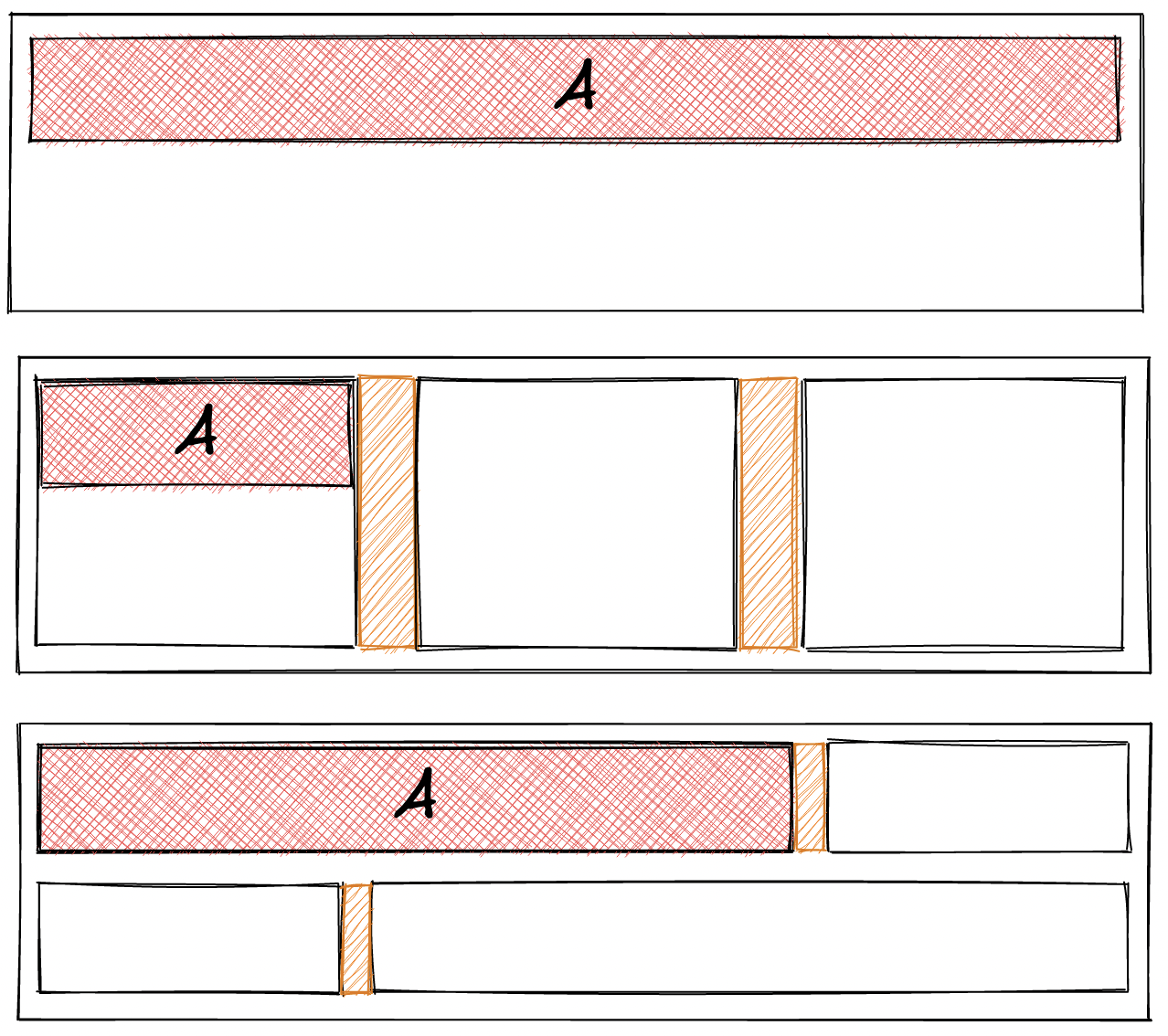
Consider the image below. A component C renders components A and B. In between A and B is a space. The question is: who declares this spacing?
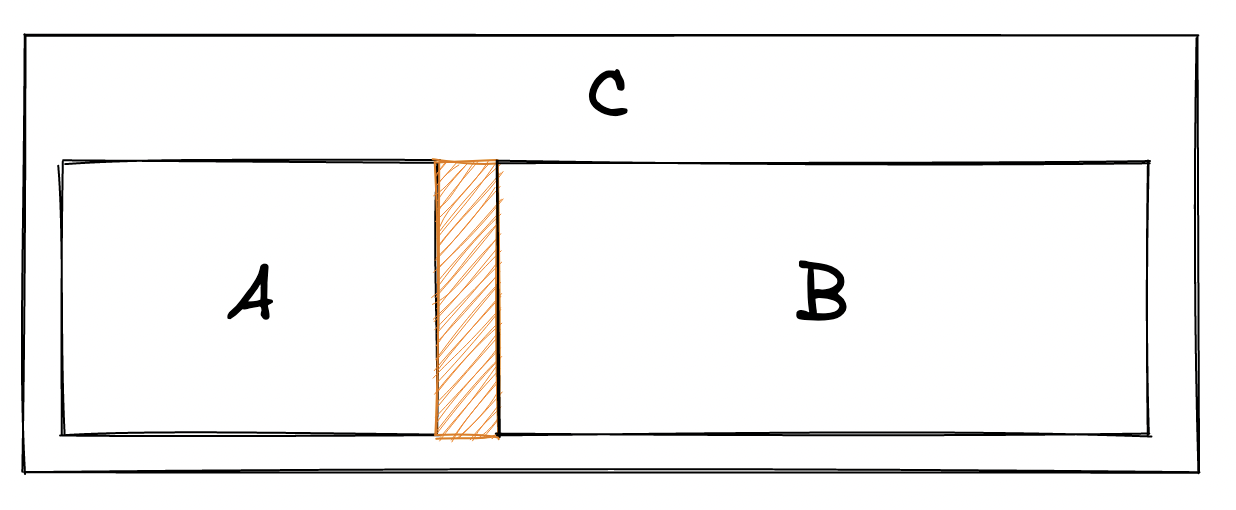
Consider the outcome if it belongs to A as a margin-right. That is, the spacing is internal to A. The problem with doing this is that the default presentation of A includes a margin-right.
Given that, what should happen in the image below? We have E, which renders A beside D, but without the spacing.
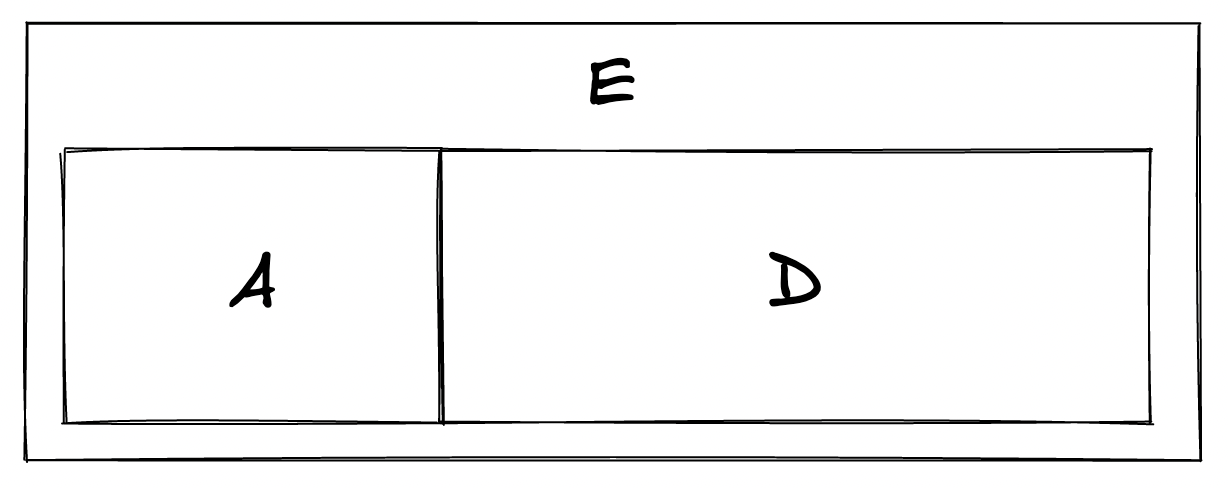
If A has an internal margin-right, we will have to override it to 0. It effectively undoes the style rule back to the default browser value. Taking such a step feels like a code smell.
const StyledA = style(A)`
margin-right: 0;
`;
A general way to avoid this problem is to say that a component should not apply margins (i.e., spacing) to the outside of itself. Therefore, the correct answer to the question is that C always declares the spacing. I have yet to find a decent counter-example to this assertion.
Components should usually take up all horizontal space given.
Most of the time, a component should take up all of the width the parent gives it. That is, the default state of most components is to take up the entire width of the something they’re inside. When a component does not take up the whole width of the page, that’s usually because it renders in a container (flex/grid/spacer/etc.) where the container is doing the constraining.
Applying this rule makes responsive pages easier to implement because almost all media query CSS can exist (where they should) in container components (flex/grid/spacer/etc.).
Components probably shouldn’t expose className or style props.
className and style break the stylistic encapsulation of the component. These attributes allow someone to apply arbitrary stylistic overrides on a whim. This hack is probably not what you want to do when the design system specification is already present in the implementation.
In an ideal scenario, a parent component should see a child component as an opaque box with very specific levers to pull (because all levers will get pulled). Someone should not be able (or need) to “reach inside” a component to fundamentally and arbitrarily change the presentation.
If we must offer an escape hatch for custom style overrides, it’s better to expose them as UNSAFE_className and UNSAFE_style.
It’s not entirely reasonable to insist on “no style overrides ever!” If there does have to be an escape hatch, it should feel terrible to do and easy to grep. The solution I stole from a friend is to prefix both of these props with UNSAFE_.
// ❌ Nothing to see here.
const btn1 = <Button className="a b c" />;
// ✅ Feels terrible. Looks gross. Easy to grep.
const btn2 = <Button UNSAFE_className="a b c" />;
className is the hook for libraries like styled-components to inject arbitrary style.
Replacing className with UNSAFE_className removes the “temptation” to wrap something with styled-components. I see this as a big win.
It also opens the door for linter rules or another tool to prevent excessive use of overrides. This check would be impossible to do with className.
Generally try to avoid extending from base element props
Extending off a base type, such as React.HTMLAttributes<HTMLButtonElement> will expand the component’s interface by several hundred keys. From what I’ve found, if we’re doing this, we’re probably trying to forward them all to some base element (button) inside your component (Button). That is:
interface Props extends React.HTMLAttributes<HTMLButtonElement> {
type?: "primary" | "secondary" | "tertiary";
disabled?: boolean;
icon?: Icon;
/* */
}
const Button: React.FC<Props> = (props) => {
const { type, disabled, icon, ...rest } = props;
/* ... */
return <button {...rest} />;
};
When building a component interface, I want to be very clear about the variants it allows. I don’t want to enable extending from the base for the same reason that I don’t want className or style props. The door opens for arbitrary modification.
Avoiding JSX spread on foreign data prevents weird bugs sometimes.
That is, I avoid any spread operator when handling external data. Yes, I don’t want to be able to blanket forward props from one component to another. (To be fair, I feel this is an excellent general rule for handling props.) Using a spread on external data has a few drawbacks:
- It can be unclear where a specific prop is coming from. Grepping doesn’t really work.
type AProps = {
thing?: string;
other?: number;
disabled?: boolean;
/* ... */
};
const A: React.FC<AProps> = (props) => {
const [disabled, setDisabled] = React.useState(false);
/* ... */
return <B {...props} disabled={props.disabled || disabled} />;
};
type BProps = {
thing?: string;
other?: number;
disabled?: boolean;
/* ... */
};
const B: React.FC<CProps> = (props) => {
const disabled = React.useContext(DisabledContext);
/**
* Whether `C` is `disabled` depends on whether
* `disabled` was passed into `A`.
*/
return <C disabled={disabled} {...props} />;
};
- It makes it possible to forward unintended props. TypeScript will not catch this.
// button.tsx
type Props = {
children: React.ReactNode;
onClick(): void;
};
export const Button = (props: Props) => {
return <button {...props} />;
};
// account.tsx
import { Button } from "./button";
const Account = () => {
// ...
const buttonProps = {
onClick() {
/* ... */
},
style: {
/* Oops... */
},
};
return <Button {...props}>Save</Button>;
};
I recommend, whenever possible, to destructure the props object and forward keys as needed. Breaking the props down removes excessive keys, allows setting defaults, and makes grepping the code easier.
Limiting “pass-through” props for child components probably scales better.
Imagine a Modal component with up to two buttons. It can be tempting to keep the modal generic and allow the buttons to be customizable with their full props:
type Props = {
// ...
primaryButtonProps?: React.ComponentProps<Button>;
secondaryButtonProps?: React.ComponentProps<Button>;
};
const Modal: React.FC<Props> = (props) => {
/* ... */
};
I think this is fine for some base-level internal Modal component that apps don’t commonly consume. Still, it can be inconsistent unless the same primaryButtonProps blob is at every call site. Further, this explicit call for all Button props leaks details about the button to the parent component—I’m thinking specifically about whether the Button becomes disabled.
Instead, the Modal should have variations that describe different visual states. The Button props (now named “Action” props) should generally be limited to a small number of things that can reasonably vary between instances.
type Props = {
type: "alert" | "info" | "confirm";
disabled?: boolean;
primaryActionProps: {
onClick(): void;
children: string;
icon?: Icon;
/* ... */
};
secondaryActionProps?: {
onClick(): void;
children: string;
icon?: Icon;
/* ... */
};
};
const Modal: React.FC<Props> = (props) => {
/* ... */
};
In my opinion, this is an improvement that moves control into the Modal. In the future, we may decide that the secondary action in the “info” modal is a link-ish-looking component instead of a button. In the former case, this is now a considerable breaking change. However, the point is that with this new interface, such details get relegated to the internals of Modal.
Most of the time, it’s a good idea to use React context for components that depend on each other.
As I understand, the originally intended use case for context is to link the data of dependent components without threading props everywhere.
For example, let’s build custom SelectMenu and SelectOption components. Without using context, we will have to pass the same onSelect handler and selected boolean to every option:
import { SelectMenu, SelectOption } from "some-walrus-lib";
const Thing = () => {
const [selected, setSelected] = React.useState<string>(null);
return (
<SelectMenu>
<SelectOption
value="a"
onSelect={setSelected}
selected={selected === "a"}
>
Option A
</SelectOption>
<SelectOption
value="b"
onSelect={setSelected}
selected={selected === "b"}
>
Option B
</SelectOption>
<SelectOption
value="c"
onSelect={setSelected}
selected={selected === "c"}
>
Option C
</SelectOption>
<SelectOption
value="d"
onSelect={setSelected}
selected={selected === "d"}
>
Option D
</SelectOption>
</SelectMenu>
);
};
With context, we can tell the SelectMenu about the currently selected value rather than having to indicate to each SelectOption whether they are currently selected:
import { SelectMenu, SelectOption } from "some-walrus-lib";
const Thing = () => {
const [selected, setSelected] = React.useState<string>(null);
return (
<SelectMenu onSelect={setSelected} selected={selected}>
<SelectOption value="a">Option A</SelectOption>
<SelectOption value="b">Option B</SelectOption>
<SelectOption value="c">Option C</SelectOption>
<SelectOption value="d">Option D</SelectOption>
</SelectMenu>
);
};
One more thing: the context should be kept internal to the library. Allowing the naked context to be imported and handled by applications creates a brittle coupling that will easily break in future upgrades.
Grouping logical components as a single object is an almost zero-cost convenience.
It’s nice if the SelectMenu and SelectOption components get exported together, strictly because their context necessitates that they must render together. This always-together-ness is a data clump, so group them into a single object.
export const Select = {
Menu: SelectMenu,
Option: SelectOption,
// ...
};
And then we end up with:
import { Select } from "some-walrus-lib";
const instance = (
<Select.Menu onClick={handleClick}>
<Select.Option value="a">Option A</Select.Option>
<Select.Option value="b">Option B</Select.Option>
<Select.Option value="c">Option C</Select.Option>
<Select.Option value="d">Option D</Select.Option>
</Select.Menu>
);
This grouping is an almost zero-cost convenience to others. It says to them, “please use these together.”
It’s a good idea to avoid rolling my own headless abstractions for browser APIs.
JavaScript browser APIs are usually nuanced enough that you should not try to reinvent the wheel. Rely on headless abstractions that are performant and remove edge cases.
I’ve run into trouble before thinking that “all I needed was 20 lines of code” before receiving a bug report saying it doesn’t work in Safari. Don’t be like me.
Shipping only deprecations with major version bumps is a lot less stressful.
Walrus is published to an internal package registry so that it can fan out across our many frontend applications. Shipping breaking changes can make updating Walrus a hassle and a blocker for product teams. If an application is a few versions behind, but a ticket requires the latest, a breaking change as part of an upgrade can be a tremendous blocker, depending on the break.
Instead, we follow an Ember-ish versioning model where major version bumps deprecate APIs/props/helpers/etc. They also include one or many codemods to fix 95%+ of deprecations.
This way, teams can upgrade Walrus immediately and just suffer through a loud console until they’re ready to do the work.
Codemods made me faster (after I became good at codemods).
For the particular situation that I’m in, writing codemods has allowed us to ship significant, sweeping changes across all codebases quickly.
Walrus versions containing a deprecation usually have a codemod to fix that deprecation. Running the codemod often means that teams don’t even see the deprecation message before problematic code is removed from their application.
Idempotent codemods are a lot less stressful.
I make sure that codemods are idempotent. A codemod run by a developer multiple times on the same module will have the same outcome as if the developer ran it once. This additional requirement is so that a codemod won’t introduce errors if they run multiple times.
Multiple times? Why would they be run multiple times? Consider the following scenario:
- The codemod runs, and the result gets merged into the main branch.
- Another pull request predating the codemod introduces a new, now invalid, module into the codebase.
- The pull request is merged.
- The merge introduces a regression into the main branch.
- We rerun the codemod to fix the issues.
There is potential to introduce a regression if the codemod is not idempotent!
Let’s say that Walrus exposes a colors object, and we decide to suffix all colors with Base (for whatever reason). So, colors.blue and colors.red become colors.blueBase and colors.redBase, respectively. If the codemod only adds the suffix, we might soon have colors.blueBaseBase if it runs multiple times. Of course, this won’t compile, but it’s a pain to go back and fix.
Codemods can avoid this trouble when they are idempotent.
Tooling for automatic upgrades has saved me weeks of work.
I’ve written tooling that bumps Walrus, runs all new codemods, and opens a pull request across all applications. If the tests pass, the upgrade can be merged quickly. Product engineers sometimes don’t even need to know that the bump happened.
This work has saved me and others hundreds of hours of tedium and exactly the kind of thing we want to automate.
Static analysis is king.
More tooling! Knowing how developers are consuming the component library is necessary for deciding what we need to work on first. Our team has built out tooling to analyze all frontend applications across the organization and answer basic questions.
The tools work something like this:
- Clone all React frontend applications.
- Glob for every source module per application.
- Parse each into an AST and collect data by querying AST.
- Merge data from all applications into a single blob.
- Analyze blob for insights.
We make it possible to check in queries that answer questions like how many times is Walrus component X wrapped in a styled-component? Which CSS properties are changed the most? Are some components only imported with others? Etc. (The questions you could ask are arbitrary, but we’re talking about component libraries here.) Imagine trying to guess the answers to these across hundreds of thousands of lines of code! You must lean on tools.
Furthermore, making these queries available via REST endpoint makes setting up dashboards and metrics easy. (And even more tools for writing JIRA tickets.) It’s nice to see graphs characterizing technical debt that moves down-and-to-the-right.
Visual regression tests are more valuable than unit tests.
Image snapshot testing with Jest is invaluable. Iterate through all variants and states of a component, take an image snapshot at each step, and compare them against the last version of the component. The suite is configurable so that any difference in the presentation will trigger a failure. Did you expect to see a difference? No? I guess you need to fix something.
Visual regression tests are a pain to set up (but definitely worth it).
The test harness involved in taking an image snapshot is pretty gnarly. It requires that the OS running the snapshot tests on your machine is the same OS on CI. If you’re running a Linux image on CI (you probably are), you must run snapshot tests in a Docker container on your MacBook. That’s because running the tests on CI will fail as Linux uses different font smoothing than MacOS. Is this solved yet? Someone email me!
Furthermore, they can be very slow to run, and an unexpected failure can be tedious to debug.
That’s it for now.
That’s all I can think of right now. If you have feedback, you can tweet, DM or send an email.